INSUBCONTINENT EXCLUSIVE:
Instagram has posted an article describing the behind-the-scenes machinery that fills the Explore tab in Instagram with new, interesting
stuff every time you open it
It a bit technical, so here are five takeaways.
Even Instagram and Facebook have limited resources
Unlike the feed, which some still would
prefer was simply chronological, the Explore tab needs to be algorithmically driven
But understanding what happening on an image-based social network and recommending new content to people is a problem that exactly as hard
as you make it.
If these companies had infinite processing power and time, they&d probably come at the question of Explore a bit differently
But as it is they need to serve hundreds of millions of people on short notice and with merely enormous computing resources
I think they put this at the top of the post so people don&t wonder why they&re cutting corners.
How Instagram algorithm works
It also
easier to experiment and iterate when you can change stuff and see results quickly, they point out.
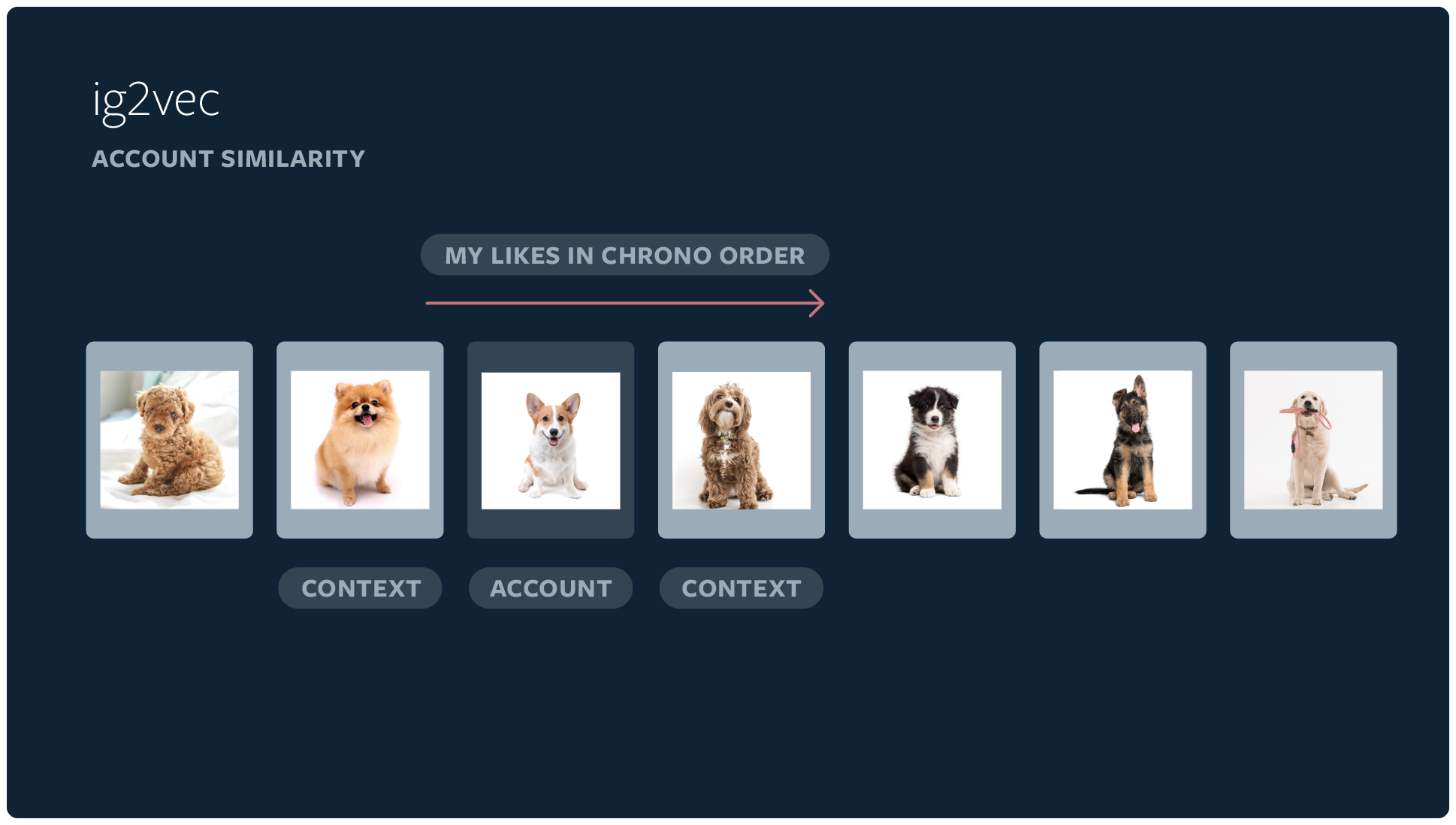
It all about the account, not the
post
So much is posted to Instagram that it would be pretty much impossible to keep track of every photo individually, for recommendation
It simpler and more efficient to track accounts, since accounts tend to have themes or topics, from a broader one like &travel& to something
highly specific, like especially round seals.
While liking one post from an account doesn&t necessarily mean you&ll like everything else
from that account, it is a good indicator that you&re at least interested in the theme of that account
Even if it was this particular post of this particular cat that you wanted to heart because it reminds you of old Mittens, if you&re liking
pictures from an account that mostly posts cats, that valuable information.
Complex habits inform the algorithm
Notably it isn&t just image
features that Instagram uses to figure out what accounts are topically linked, though of course that kind of thing can be detected too
They also use your behavior.
For instance, when you like several posts in a row, they&re more likely to be linked in some way even if
Instagram algorithms can&t quite see it:
If an individual interacts with a sequence of accounts in the same session, it more likely to be
topically coherent compared with a random sequence of accounts from the diverse range of Instagram accounts
This helps us identify topically similar accounts.
People just tend to look into stuff that way, going from one travel-focused account to
the next, or focusing on animals because they need a pick-me up
All that information gets sucked up by the algorithm and inspected for relevance
Of course deliberate actions like &see fewer posts like this& and blocking accounts has a lot of weight as well.
From &seed accounts& to a
top 25
The process of getting from a couple billion posts to just two dozen can be pretty difficult, but you can cut the problem down to
manageable size by limiting the Explore tab to accounts linked in some way to accounts the user has already liked or saved posts from
These are called &seed accounts& because everything else in the process really grows out of them.
Because of how the machine learning system
represents accounts and their topics inside itself, it super easy for it to find a couple hundred similar accounts.
Imagine if you know
someone likes a particular reddish-orange marble and you need to find some more like it
If you just dip your hand into a sack of marbles you&re unlikely to find one quickly
Even if you pour them out on the floor you&ll still have to hunt around for a bit
But if you&ve already organized them by color, all you have to do is reach into the general vicinity of the marble they like and you&re
almost guaranteed to pick a winner.
The machine learning model does that by giving all these accounts a sort of location in a virtual space,
and the closer two are in that space, the closer they are topically.
So the really hard part of paring down a set of billions to a set of
hundreds is basically already accomplished by the way the accounts are classified.
From there Instagram does three passes with neural
networks of increasing complexity.
First, slightly confusingly, is a simpler, combined version of the next two processes, which takes it
This is a little weird, but think about it this way: This neural network has seen steps 2 and 3 happen many times and has a pretty good idea
Sort of like if you&d seen cookies get made enough times that you could guess at a recipe
You&d probably get close, but you also wouldn&t want to publish it to like a hundred million people
So this step just gets the obvious stuff right.
Second is a computationally cheap neural network that uses way more signals than the simple
topical similarity mentioned above
Here where your individual likes come into play, as well as the deeper data about accounts
You like travel, sure, but in particular you like couples traveling — both things the marble-sorting algorithm above can help with
Other parameters, like a post general popularity, or actually its being different from the other posts in the mix, figure in as well
That skims another 100 off the top, leaving 50.
Third is a computationally expensive version of the above, which does another pass on those
50 and cuts them in half, basically by looking closer and taking the time to include, perhaps, a thousand data points each rather than a
hundred.
I guess that was kind of long for a &takeaway.& Don&t worry, the next one is quick.
And of course, no
&We want to make sure the
content we recommend is both safe and appropriate for a global community of many ages on Explore,& they write
&Using a variety of signals, we filter out content we can identify as not being eligible to be recommended.&
So now you know why you don&t
get any of that in Explore.
Instagram now demotes vaguely ‘inappropriate& content