
 11
11
Technology
A data set of more than 3 million Facebook users and a variety of their personal details collected by Cambridge researchers was available for anyone to download for some four years, New Scientist reports. Itlikely only one of many places where such huge sets of personal data collected during a period of permissive Facebook access terms have been obtainable.
The data were collected as part of a personality test, myPersonality, which, according to its own wiki (now taken down), was operational from 2007 to 2012, but new data was added as late as August of 2016. It started as a side project by the Cambridge Psychometrics CentreDavid Stillwell (now deputy director there), but graduated to a more organized research effort later. The project &has close academic links,& the site explains, &however, it is a standalone business.& (Presumably for liability purposes; the group never charged for access to the data.)
Though &Cambridge& is in the name, thereno real connection to Cambridge Analytica, just a very tenuous one through Aleksandr Kogan, which is explained below.
Like other quiz apps, it requested consent to access the userprofile (friends& data was not collected), which combined with responses to questionnaires produced a rich data set with entries for millions of users. Data collected included demographics, status updates, some profile pictures, likes and lots more, but not private messages or data from friends.
Exactly how many users are affected is a bit difficult to say: the wiki claims the database holds 6 million test results from 4 million profiles (hence the headline), though only 3.1 million sets of personality scores are in the set and far less data points are available on certain metrics, such as employer or school. At any rate, the total number is on that order, though the same data is not available for every user.
 Although the data is stripped of identifying information, such as the useractual name, the volume and breadth of it makes the set susceptible to de-anonymization, for lack of a better term. (I should add there is no evidence that this has actually occurred; simple anonymizing processes on rich data sets are just fundamentally more vulnerable to this kind of reassembly effort.)
Although the data is stripped of identifying information, such as the useractual name, the volume and breadth of it makes the set susceptible to de-anonymization, for lack of a better term. (I should add there is no evidence that this has actually occurred; simple anonymizing processes on rich data sets are just fundamentally more vulnerable to this kind of reassembly effort.)
This data set was available via a wiki to credentialed academics who had to agree to the teamown terms of service. It was used by hundreds of researchers from dozens of institutions and companies for numerous papers and projects, including some from Google, Microsoft, Yahoo and even Facebook itself. (I asked the latter about this curious occurrence, and a representative told me that two researchers listed signed up for the data before working there; itunclear why in that case the name I saw would list Facebook as their affiliation, but there you have it.)
This in itself is in violation of Facebookterms of service, which ostensibly prohibited the distribution of such data to third parties. As we&ve seen over the last year or so, however, it appears to have exerted almost no effort at all in enforcing this policy, as hundreds (potentially thousands) of apps were plainly and seemingly proudly violating the terms by sharing data sets gleaned from Facebook users.
In the case of myPersonality, the data was supposed to be distributed only to actual researchers; Stillwell and his collaborator at the time, Michal Kosinski, personally vetted applications, which had to list the data they needed and why, as this sample application shows:
I am a full-time faculty member. [IF YOU ARE A STUDENT PLEASE HAVE YOU SUPERVISOR REQUEST ACCESS TO THE DATA FOR YOU.] I read and agree with the myPersonality Database Terms of Use. [SERIOUSLY, PLEASE DO READ IT.] I will take responsibility for the use of the data by any students in my research group.
I am planning to use the following variables: * [LIST THE VARIABLES YOU INTEND TO * USE AND TELL US HOW * YOU PLAN TO ANALYZE THEM.]
One lecturer, however, published their credentials on GitHub in order to allow their students to use the data. Those credentials were available to anyone searching for access to the myPersonality database for, as New Scientist estimates, about four years.
This seems to demonstrate the laxity with which Facebook was policing the data it supposedly guarded. Once that data left company premises, there was no way for the company to control it in the first place, but the fact that a set of millions of entries was being sent to any academic who asked, and anyone who had a publicly listed username and password, suggests it wasn&t even trying.
A Facebook researcher actually requested the data in violation of his own companypolicies. I&m not sure what to conclude from that, other than that the company was utterly uninterested in securing sets like this and far more concerned with providing against any future liability. After all, if the app was in violation, Facebook can simply suspend it — as the company did last month, by the way — and lay the whole burden on the violator.
&We suspended the myPersonality app almost a month ago because we believe that it may have violated Facebookpolicies,& said FacebookVP of product partnerships, Ime Archibong, in a statement. &We are currently investigating the app, and if myPersonality refuses to cooperate or fails our audit, we will ban it.&
In a statement provided to TechCrunch, David Stillwell defended the myPersonality projectdata collection and distribution.
&myPersonality collaborators have published more than 100 social science research papers on important topics that advance our understanding of the growing use and impact of social networks,& he said. &We believe that academic research benefits from properly controlled sharing of anonymised data among the research community.&
In a separate email, Michal Kosinski also emphasized the importance of the published research based on their data set. Herea recent example looking into how people assess their own personalities versus how those who know them do, and how a computer trained to do so performs.
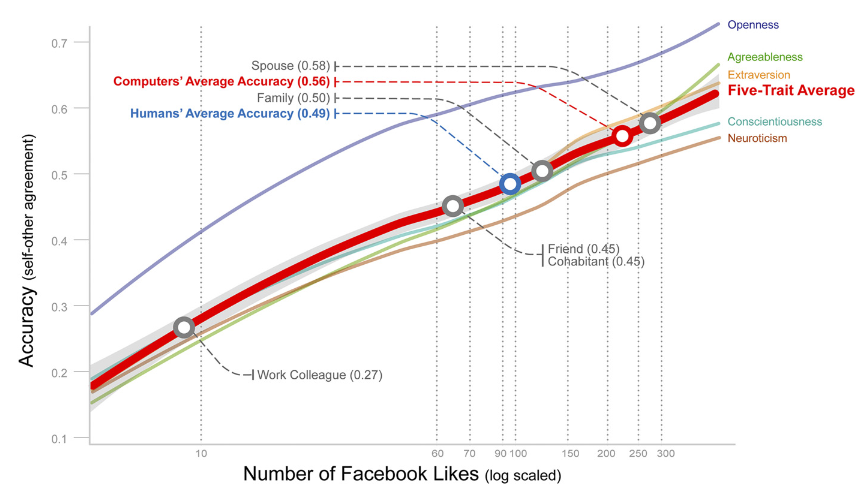
From the research paper based on myPersonalitydatabase. The computer performed almost as well as a spouse.
&Facebook has been aware of and has encouraged our research since at least 2011,& the statement continued. Ithard to square this with Facebookallegation that the project was suspended for policy violations based on the language of its redistribution terms, which is how a company spokesperson explained it to me. The likely explanation is that Facebook never looked closely until this type of profile data sharing became unpopular, and usage and distribution among academics came under closer scrutiny.
Stillwell said (and the Centre has specifically explained) that Aleksandr Kogan was not in fact associated with the project; he was, however, one of the collaborators who received access to the data like those at other institutions. He apparently certified that he did not use this data in his SCL and Cambridge Analytica dealings.
The statement also says that the newest data is six years old, which seems substantially accurate from what I can tell except, for a set of nearly 800,000 users& data regarding the 2015 rainbow profile picture filter campaign, added in August 2016. That doesn&t change much, but I thought it worth noting.
Facebook has suspended hundreds of apps and services and is investigating thousands more after it became clear in the Cambridge Analytica case that data collected from its users for one purpose was being redeployed for all sorts of purposes by actors nefarious and otherwise. One is a separate endeavor from the Cambridge Psychometrics Centre called Apply Magic Sauce; I asked the researchers about the connection between it and myPersonality data.
The takeaway from the small sample of these suspensions and collection methods that have been made public suggest that during its most permissive period (up until 2014 or so) Facebook allowed the data of countless users (the totals will only increase) to escape its authority, and that data is still out there, totally out of the companycontrol and being used by anyone for just about anything.
Researchers working with user data provided with consent aren&t the enemy, but the total inability of Facebook (and to a certain extent the researchers themselves) to exert any kind of meaningful control over that data is indicative of grave missteps in digital privacy.
Ultimately it seems that Facebook should be the one taking responsibility for this massive oversight, but as Mark Zuckerbergperformance in the Capitol emphasized, itnot really clear what taking responsibility looks like other than an appearance of contrition and promises to do better.
- Details
- Category: Technology
Read more: Anyone could download Cambridge researchers’ 4-million-user Facebook data set for years
Write comment (100 Comments)
Seattlecity council voted unanimously to approve a new tax on the largest employers in the city, despite strong opposition by Amazon and other affected companies. The tax, on companies with more than $20 million in receipts, will amount to about $275 per employee and is intended for use in improving conditions for the cityhomeless.
The original proposal was nearly twice that, but was amended as a compromise measure after local businesses protested. Amazon was the most visible of them, making the dramatic public threat of suspending construction of one of its many skyscrapers in the city and repurposing another.
While the idea that a company would simply abandon a multi-million-dollar investment halfway isn&t really credible, changes to its scheduling, budget and usage plan would certainly affect local contractors — which is why many of the latter showed up to oppose the tax on Amazonbehalf. A heated confrontation occurred between opponents and proponents gathered in front of AmazonSpheres earlier this month.
The idea of laborers lobbying in favor of Amazon, which is frequently decried as an extremely labor-unfriendly company, seems odd, but in this case at least the train of thought is clear. It should also be mentioned that Amazon has worked to ease the plight of Seattle homeless with a planned shelter at the base of one of its buildings and other contributions.
Zillow and Expedia also voiced concerns, alongside many other local businesses, in an open letter. &We oppose this approach, because of the message it sends to every business: if you are investing in growth, if you create too many jobs in Seattle, you will be punished,& the letter reads in part.
Although opposition seems to have succeeded in reducing the tax burden, it did little to convince the council that the tax itself was unsound, as todayvote indicates.
&This progressive revenue stream balances the needs of our small business community, while ensuring we have the funding we need to provide critical housing and health services,& said Councilmember Teresa Mosqueda in a statement accompanying the vote. GeekWire was at the meeting and has some other interesting quotes from both sides.
The modified tax should generate some $50 million, much of which will be dedicated to &deeply affordable& housing in the city to be made available to people below the poverty line, with some going to emergency shelters and other social services. Around $11 million of that will come from Amazon. This would significantly increase (in fact, nearly double based on some estimates) existing spending along these lines.
The tax would last for five years, after which it would have to be reauthorized.
Amazon, for its part, seems to have abandoned its immediate threats for new, more vague ones. In a statement from VPDrew Herdener provided to TechCrunch, it said:
We are disappointed by todayCity Council decision to introduce a tax on jobs. While we have resumed construction planning for Block 18, we remain very apprehensive about the future created by the councilhostile approach and rhetoric toward larger businesses, which forces us to question our growth here.
- Details
- Category: Technology
Read more: Seattle passes new tax on large companies despite Amazon’s howls of protest
Write comment (94 Comments)
I&ve spent a good chunk of my life piecing together various LEGO projects… but even the craziest stuff I&ve built pales in comparison to this. Ita fully functioning pinball machine built entirely out of official LEGO parts, from the obstacles on the playfield, to the electronic brains behind the curtain, to the steel ball itself.
Creator Bre Burns calls her masterpiece &BennySpace Adventure,& theming the machine around LEGOclassic ‘lil blue space man. Itmade up of more than 15,000 LEGO bricks, multiple Mindstorms NXT brains working in unison, steel castor balls borrowed from a Mindstorms kit, plus lights and motors repurposed from a bunch of other sets. Bre initially set out to build the project for exhibition at the LEGO fan conference BrickCon in October of last year, and itjust grown and grown ever since.
Bre told the LEGO-enthusiast site Brothers Brick that shespent somewhere between 200 and 300 hours so far on this project. Want to know more They&ve got a great breakdown of the entire project right over here.
- Details
- Category: Technology
Read more: This functional pinball machine is built entirely of LEGO
Write comment (91 Comments)
Autonomous systems are coming. In fact, they&re already here, thanks to AlphabetWaymo, Uber and smaller startups like Aurora, Embark Trucks and Voyage. Although there have a been a couple of fatal crashes involving autonomous software, the consensus seems to be that self-driving is still the way to go.
Last year, 37,150 people died in car accidents nationwide, according to a statistical projection from the U.S. Department of Transportation National Highway Traffic Safety Administration. Worldwide, nearly 1.3 million people die every year, according to the Association for Safe International Road Travel.
&The only plausible strategy that we have as a society to get to zero [fatalities] is driverless,& Embark CEO Alex Rodrigues told me at TC Sessions: Robotics last week. &Itnot plausible to get all the drunk or distracted or unsafe humans off the road. The only realistic way we can get to zero is driverless.&
Rodrigues added that itnot a question of whether or not we should do driverless, but &ita question of how can we roll it out safely and responsibly and how soon is it ready for prime time.&
As it stands today, itclear that most autonomous vehicles are not ready, Rodrigues said.As he noted, itobvious that companies aren&t ready today, but to determine when companies will be ready will require &a judgment that is going to be very nuanced.&
Instead of companies reporting thousands of miles without disengagements (human interventions), he said we need to see millions of miles.
Waymo, which has driven over 4 million miles across the U.S., has a disengagement rate of 0.18 events per 1,000 miles driven, according to the California DMVannual report in January. Thatabout 5,555 miles between engagements on average.Cruise, on the other hand, had an average of 4,600 miles between disengagements.
The idea that a software system will never fail is a fallacy, Voyage CEO Oliver Cameron said. He noted that software fails all the time, but that itabout having appropriate levels of redundancy in the system.
&Ithow you handle those [failures] gracefully thatreally crucial,& Cameron said.
Still, many companies are working on autonomous ride-hailing services. Drive.ai, for example, recentlyannounced its plans to launch an autonomous ride-hailing network in Frisco, Texas. And General Motors& Cruise says iton track to launch its ride-hailing service by 2019.But autonomous nationwide ride-hailing is probably a bit further down the road.
&I think thatgoing to take a while,& Aurora CEO Chris Urmson told me at Robotics. &I expect that the technology is going to be deployed in city by city for a long time.&
- Details
- Category: Technology
Read more: Embark CEO says autonomous driving is the only way we’ll get to zero fatalities
Write comment (100 Comments)A lot of money — about $140 billion — is lost every year in the U.S. healthcare system thanks to inefficient management of basic internal operations, according to a study from the Journal of the American Medical Association.
While there are many factors that contribute to the woeful state of healthcare in the U.S., with greed chief among them, the 2012 study points to one area where hospitals have nothing to lose and literally billions to gain by improving their patient flows.
The problem, according to executives and investors in the startup Qventus, is that hospitals can&t invest in new infrastructure to streamline the process thatable to work with technology systems that are in some cases decades old — and with an already overtaxed professional staff.
Thatwhy the founders of Qventus decided to develop a software-based service that throws out dashboards and analytics tools and replaces it with a machine learning-enhanced series of prescriptions for hospital staff to follow when presented with certain conditions.
Qventus& co-founder and chief executive Mudit Garg started working with hospitals 10 years ago and found the experience &eye-opening.&
&There are lots and lots of people who really really care about giving the best care to every patient, but it depends on a heroic effort from all of those individuals,& Garg said. &It depended on some amazing manager going above and beyond and doing some diving catch to make things work.&
As a software engineer, Garg thought there was a simple solution to the problem — applying data to make processes run more effectively.
In 2012 the company started out with a series of dashboards and data management tools to provide visibility to the hospital administrators and operators about what was happening in their healthcare facilities. But, as Garg soon discovered, when doctors and nurses get busy, they don&t love a dashboard.
From the basic analytics, Garg and his team worked to make the data more predictive — based on historical data about patient flows, the system would send out notifications about how many patients a facility could expect to come in at almost any time of day.
But even the predictive information wasn&t useful enough for the hospitals to act on, so Garg and company went back to the drawing board.
What they finally came up with was a solution that used the data and predictive capabilities to start suggesting potential recipes for dealing with situations in hospitals. Rather than saying that a certain number of patients were likely to be admitted to the hospital, the software suggests actions for addressing the likely scenarios that could occur.
For instance, if there are certain times when the hospital is getting busier, nurses can start discharging patients in anticipation of the need for new capacity in an ICU, Garg said.

Photo courtesy of Paul Burns
That product, some six years in the making, has garnered the attention of a number of top investors in the healthcare space. Mayfield Fund and Norwest Venture Partners led the companyfirst round, and Qventus managed to snag a new $30 million round from return investors and new lead investor, Bessemer Venture Partners. Strategic backer New York Presbyterian Ventures, the investment arm of the famed New York hospital system, also participated.
So far, Qventus has raised $43 million for its service.
As a result of the deal, Stephen Kraus, a partner at Bessemer, will take a seat on the companyboard of directors.
&Hospitals are under tremendous pressure to increase efficiency, improve margins and enhance patient experience, all while reducing the burden on frontline teams, and they currently lack tools to use data to achieve operational productivity gains,& said Kraus, in a statement.
For Kraus, the application of artificial intelligence to operations is just as transformative for a healthcare system, as its clinical use cases.
&We&ve been looking at this space broadly… AI and ML to improve healthcare… image interpretation, pathology slide interpretation… thatall going to take a longer time because healthcare is slow to adapt.& said Kraus. &The barriers to adoption in healthcare is frankly the physicians themselves…the average primary care doc is seeing 12 to 20 patients a day… they barely want to adopt their [electronic medical health records]… The idea that they&re going to get comfortable with some neural network or black box technology to change their clinical workflow vs. Qventus which is clinical workflow to strip out cost… Thatlower hanging fruit.&
- Details
- Category: Technology

Netflix today announced that it will release a second season of Lost in Space, the big-budget sci-fi program that debuted in April.
The series is a revamp of the original show from the 1960s. Season One, which included 10 episodes, follows the Robinson family on their journey from Earth to Alpha Centauri. Along the way, they stumble across extraterrestrial life and a wide array of life-or-death situations.
Many of the elements from the original show have been reimagined, not least of which being the role of Mr. Smith going to Parker Posey, who plays the delightfully wicked villain.
We reviewed the show on the Original Content podcast in this episode, and struggled to find any meaningful flaws.
- Details
- Category: Technology
Read more: Lost in Space is coming back for a second season
Write comment (91 Comments)Page 5404 of 5614